
“Two philosophies, one goal: ship fast and stay reliable”
Introduction
If you have spent any time in the cloud-native or platform engineering space, you have heard both terms thrown around – often interchangeably. DevOps engineer. SRE. Site Reliability Engineer. Platform engineer. The titles blur together, the job descriptions overlap, and job postings seem to use them as synonyms.
They are not synonyms. But they are not opposites either.
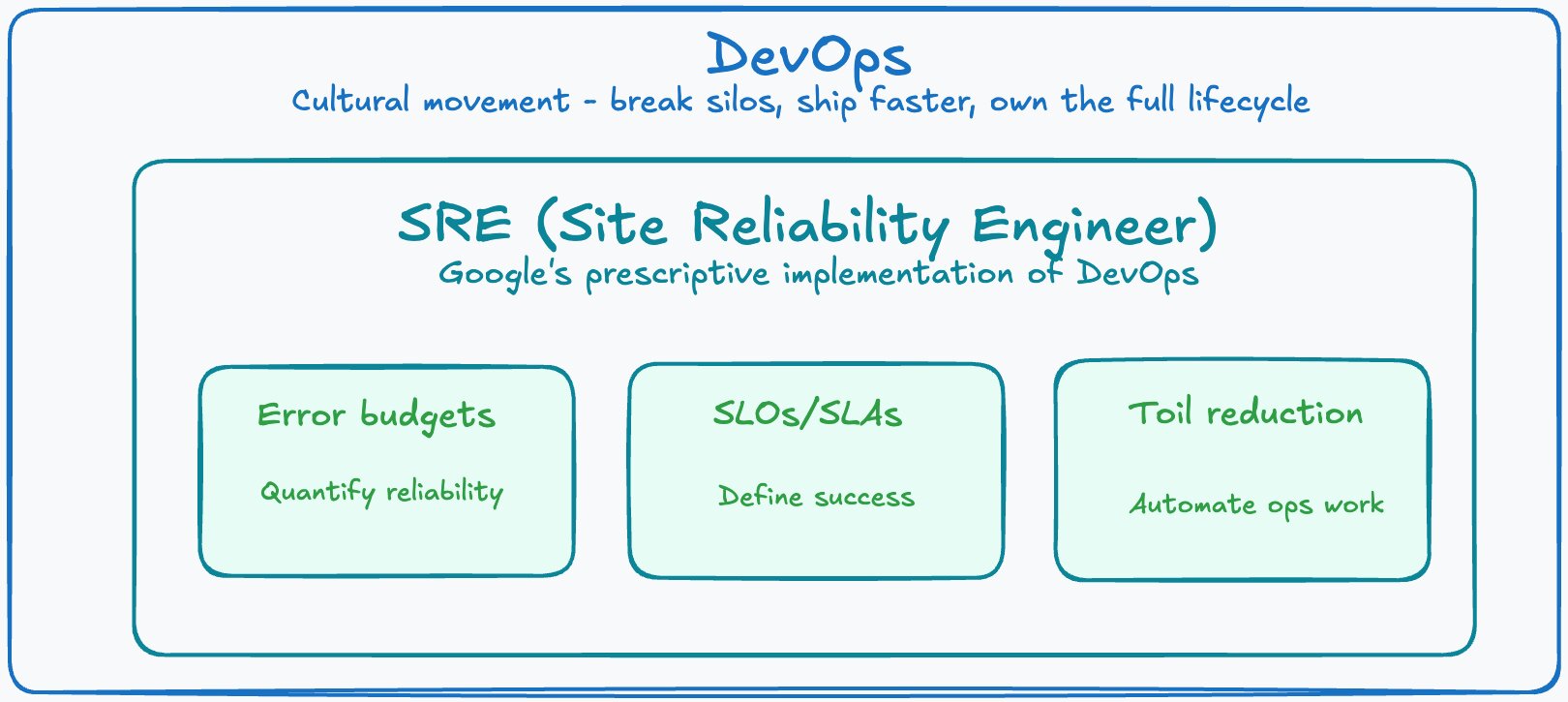
DevOps is a cultural movement – a philosophy that says development and operations teams should work as one, sharing ownership of the entire software lifecycle from code commit to production incident. SRE, or Site Reliability Engineering, is Google’s answer to a specific question: what does it actually look like to operationalise that philosophy at scale?
In this post, we will walk through both from first principles: what they stand for, how they differ in practice, where they overlap, and how to decide which model fits your team.
[Figure 1 — Philosophy Overview]
1. What is DevOps?
DevOps emerged around 2008–2009 as a reaction to the wall between software development and IT operations. The traditional model was simple and painful: developers wrote code, threw it over the fence to ops, and ops ran it. When things broke in production, neither side had full context, and both sides had an incentive to blame the other.
DevOps tore down that wall – or at least tried to. The core principles are:
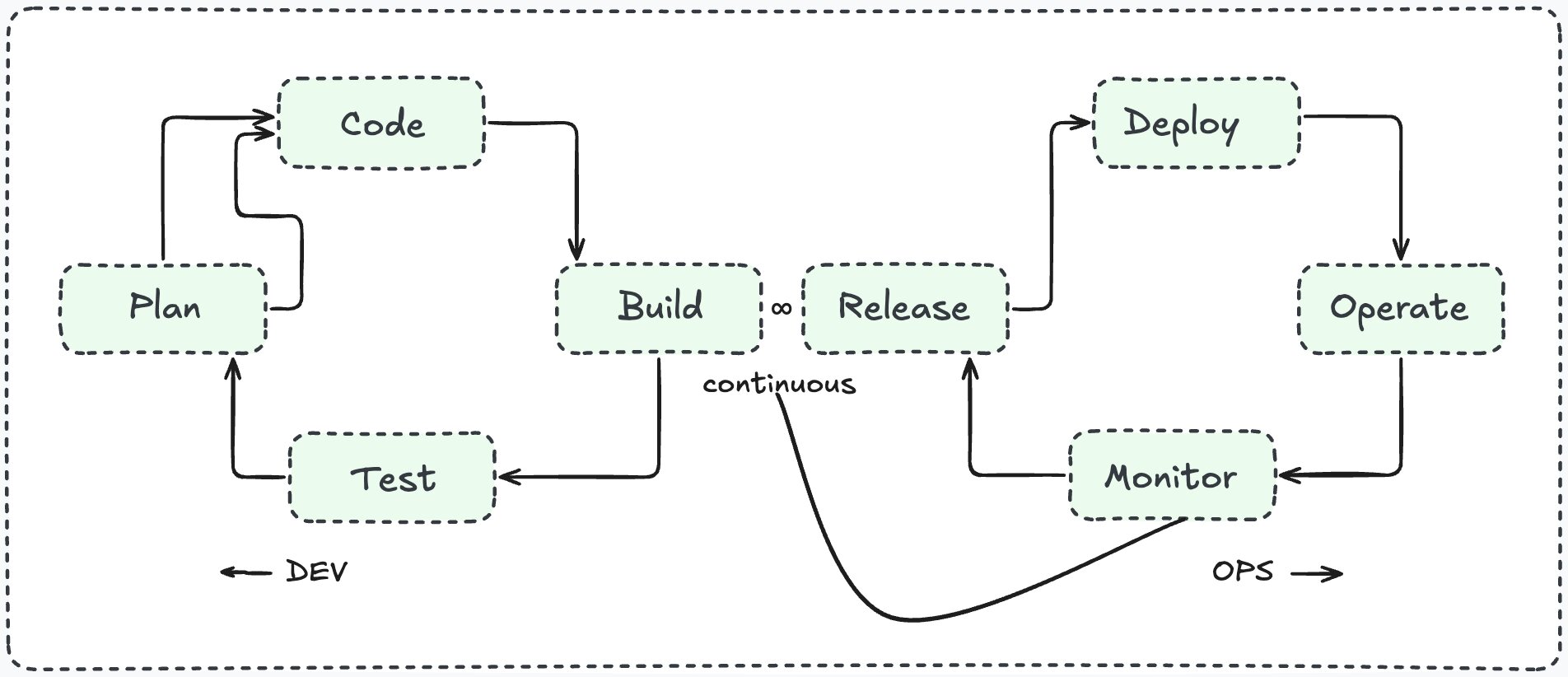
- Shared ownership of the full lifecycle, from design to deployment to incident response
- Continuous integration and continuous delivery (CI/CD) to ship smaller, safer changes frequently
- Infrastructure as code, so environments are reproducible and version-controlled
- Blameless postmortems and a learning culture when things go wrong
- Monitoring and observability as a first-class concern, not an afterthought
Crucially, DevOps is not a job title – it is a culture. A DevOps engineer is someone who embodies this culture: they write code, they automate pipelines, they manage infrastructure, and they own what they ship. But the real goal of DevOps is that every engineer thinks this way.
[Figure 2 – DevOps Infinity Loop]
Key insight DevOps is a philosophy. It tells you what to aim for. It does not tell you exactly how to get there, what metrics to track, or how much ops work is too much ops work.
2. What is SRE?
Site Reliability Engineering was invented at Google around 2003 by Ben Treynor Sloss. The founding idea was straightforward: if you hire software engineers to do operations work, they will automate themselves out of it. The result is a discipline that treats operations as a software engineering problem.
SRE is prescriptive, whereas DevOps is principles-based. It introduces concrete mechanisms:
Service Level Objectives (SLOs)
An SLO is a target reliability level for a service, expressed as a percentage over a time window. For example: 99.9% of requests must succeed within 200ms over a rolling 30-day window. SLOs are agreed upon between the SRE team and the product team and become the shared definition of “good enough”.
Service Level Indicators (SLIs)
An SLI is the actual measurement that feeds into an SLO. Availability, latency, error rate, throughput — these are typical SLIs. The SLO defines the target; the SLI tracks reality against it.
Error Budgets
This is the most powerful SRE concept. If your SLO is 99.9% uptime per month, you have 0.1% of the month as your error budget – roughly 43 minutes of acceptable downtime. As long as the budget remains, teams can ship freely. When the budget is exhausted, feature releases pause until reliability is restored. The error budget transforms reliability from a vague aspiration into a shared, data-driven contract between engineering and product.

[Figure 3 — Error Budget Decision Flow]
Toil reduction
SRE formalises the concept of toil – manual, repetitive, automatable work that scales linearly with traffic. Google’s rule is that SREs should spend no more than 50% of their time on toil. The rest must go to engineering work that reduces future toil. This prevents SRE teams from becoming glorified sysadmins.
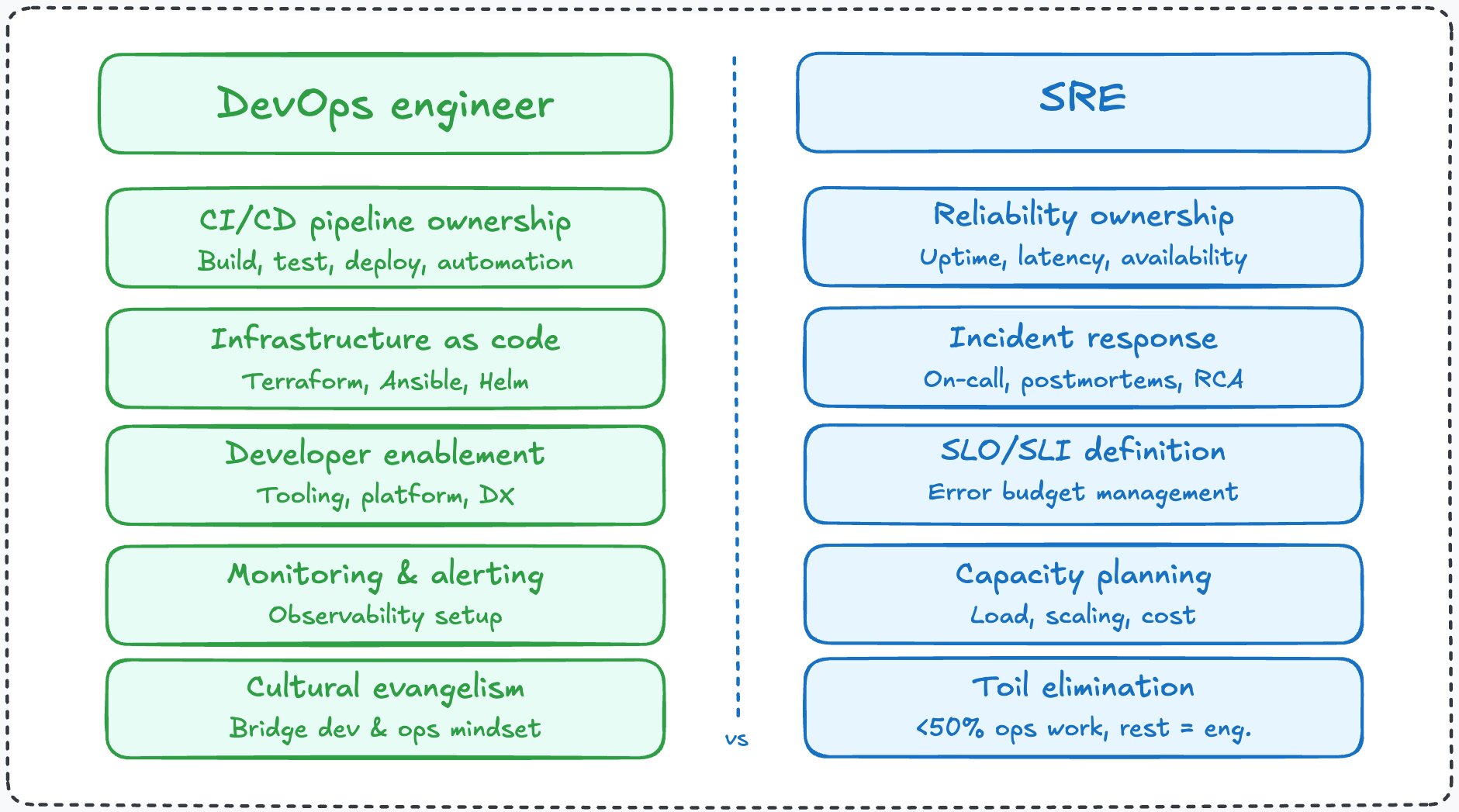
3. Key differences
Now that we understand each discipline, let us map the practical differences side by side.

The most important distinction is scope. DevOps is about the entire engineering culture – breaking silos, enabling faster delivery, and fostering collaboration. SRE is about a specific function within that culture: ensuring that what gets shipped stays reliable.
[Figure 4 — Responsibilities Comparison]
4. Where they overlap
5. When to use each model
DevOps makes sense when…
- You are a startup or a small engineering team where everyone needs to wear multiple hats
- You are beginning the journey from a siloed, waterfall organisation toward continuous delivery
- You need cultural transformation more than operational rigour
- Your services are early-stage and do not yet have well-defined reliability requirements
SRE makes sense when…
- You are running services at scale where downtime has real business or user impact
- You need a structured, data-driven way to balance feature velocity and reliability
- You have defined SLAs with customers and need SLOs to back them up
- On-call is becoming chaotic, and you need runbooks, escalation paths, and toil caps
- Engineering time is being eaten by repetitive operational work
6. Common misconceptions
“SRE replaced DevOps”
“SREs just do ops work”
“DevOps means no operations team”
Conclusion
Comments (...)
You must be signed in to join the discussion.